들어가며
SolveMeUp 커뮤니티에 검색 기능을 구현하며 대표적인 대안인 MySQL LIKE 절과 Full-Text Search의 한계를 분석하고, Elasticsearch를 도입하면서 트랜잭션 정합성까지 확보한 과정을 기록합니다.
문제 상황 가정
사용자는 커뮤니티에서 “우선순위 큐”를 검색했을 때 아래와 같은 게시글들이 모두 검색되어야 합니다.
- “우선순위 큐 개념 정리”
- “우선순위큐로 다익스트라 구현하기”
- “Priority Queue 활용 문제 풀이”
그리고 단순히 검색 결과를 나열하기 보단 제목과 본문을 함께 검색하되 제목에 키워드가 포함된 글이 내용에만 언급된 글보다 먼저 노출 되어야합니다. 제목이 “우선순위 큐 개념 정리”인 글은 내용에서 우선순위 큐를 한 번 언급한 글보다 사용자가 찾고 있을 확률이 높기 때문입니다.
따라서 두 가지 요구사항을 도출할 수 있습니다.
- 형태소 단위 매칭: 띄어쓰기나 조사에 관계없이 “우선순위큐”, “우선 순위 큐” 모두 검색
- 필드별 가중치 기반 정렬: 제목 매칭 > 본문 매칭 순으로 결과 정렬
후보 방식 비교
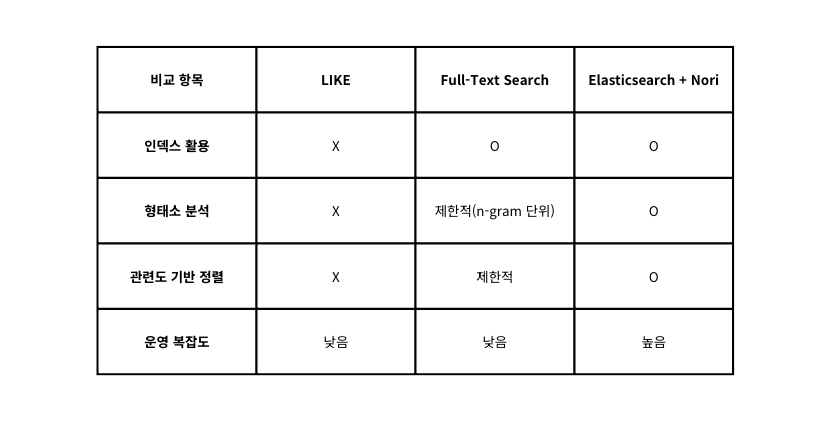
1. LIKE 절 조회
SELECT * FROM post WHERE title LIKE '%우선순위 큐%' OR content LIKE '%우선순위 큐%';
가장 단순한 방법이지만 명확한 한계가 존재합니다.
형태소 분석 불가
“우선순위큐”로 검색하면 “우선 순위 큐”는 매칭되지 않습니다. 띄어쓰기, 조사, 어미 변화를 전혀 처리하지 못합니다.
Full Table Scan
%keyword% 패턴은 와일드카드가 앞에 위치하기 때문에 B+Tree 인덱스를 활용할 수 없습니다. 데이터가 늘어날수록 조회 성능이 선형적으로 저하됩니다.
검색 품질의 부재
단순히 문자열 포함 여부만 판단하므로 검색 결과 간 관련도 점수 매길 수 없습니다. 제목에 정확히 일치하는 글과 본문 끝에 한 번 언급된 글이 동일하게 취급됩니다.
2. MySQL Full-Text Search
MySQL 5.7부터 InnoDB에서도 Full-Text Index를 지원합니다.
LIKE 절보다는 나은 방법입니다. Full-Text Index를 통해 역인덱스(inverted index) 구조를 활용하므로 Full Table Scan을 피할 수 있고, MATCH ... AGAINST 구문으로 관련도 점수 기반 정렬도 가능합니다. 하지만 여전히 한계가 존재합니다.
의미 기반 검색 불가능
MySQL의 ngram parser는 단순히 n글자씩 잘라서 토큰을 만듭니다. “우선순위큐”를 2-gram으로 분석하면 “우선”, “선순”, “순위”, “위큐”가 됩니다. 형태소 단위(“우선”, “순위”, “큐”)로 분리되지 않기 때문에 “순위” 단독 검색 시 관련 없는 문서까지 매칭되는 문제가 발생할 수 있습니다.
검색 기능의 확장 어려움
오타 보정(fuzzy matching), 동의어 처리, 초성 검색, 필드별 가중치 부여 같은 검색 기능은 MySQL Full-Text Search만으로는 구현하기 어렵습니다.
3. Elasticsearch + Nori Analyzer
Elasticsearch는 Apache Lucene 기반의 분산 검색 엔진으로, 역색인(Inverted Index) 구조를 사용합니다. 여기에 한국어 형태소 분석기인 Nori를 결합하면 위의 문제들을 해결할 수 있습니다.
물론 Elasticsearch를 별도로 운영해야 하므로 인프라 복잡도가 높아지는 단점이 있습니다. 하지만 알고리즘 커뮤니티 특성상 “우선순위 큐”, “너비 우선 탐색”, “다이나믹 프로그래밍” 같은 한국어 복합 키워드 검색이 되어야 했고 이 검색을 MySQL만으로는 확보할 수 없다고 판단하여 Elasticsearch 쓰기로 결정했습니다.
Nori Analyzer
Nori는 Elasticsearch에서 공식으로 제공하는 한국어 형태소 분석 플러그인입니다.
{
"analysis": {
"analyzer": {
"nori_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer",
"filter": ["nori_part_of_speech", "nori_readingform", "lowercase"]
}
}
}
}
구성의 역할을 살펴보면
- nori_tokenizer: 한국어를 형태소 단위로 분리합니다. “우선순위큐” → “우선”, “순위”, “큐”
- nori_part_of_speech: 검색에 불필요한 조사, 어미 등을 제거합니다. “우선순위큐로” → “우선순위큐”
- nori_readingform: 한자를 한글 읽기로 변환합니다.
- lowercase: 영문을 소문자로 정규화합니다. “BFS” → “bfs”
이렇게 하면 “우선순위큐로 풀었습니다”라는 문장이 [“우선”, “순위”, “큐”, “풀”]로 토큰화되어, 사용자가 “우선 순위 큐”로 검색해도 매칭됩니다.
정합성 문제
Elasticsearch를 도입하면 데이터가 MySQL과 Elasticsearch 두 곳에 존재하게 됩니다. 여기서 단순히 동기적으로 처리할 경우 정합성에 문제가 생길 것이라고 생각했습니다.
동기 방식의 문제점
처음에 생각한 게시글 저장과 ES 인덱싱을 하나의 트랜잭션 안에서 처리하는 것입니다.
@Transactional
public PostResponse createPost(Long userId, PostCreateRequest request) {
Post post = Post.create(user, request.title(), request.content());
Post savedPost = postRepository.save(post); // 1. DB 저장
postESRepository.save(PostDocument.from(savedPost)); // 2. ES 인덱싱
return PostResponse.from(savedPost);
}
이 경우 RDB 저장과 ES 인덱싱 중 어느 한쪽이라도 실패하면 두 저장소 간의 정합성을 보장할 수 없다고 판단했습니다.
따라서 DB 트랜잭션과 ES 인덱싱을 분리하고, 코드 채점 파이프라인에서 사용하고 있던 RabbitMQ를 활용하여 커밋 이후에 비동기로 인덱싱하는 구조를 설계하면 어느정도의 정합성을 보장하도록 했습니다.
해결: 트랜잭션 분리 + 큐 기반 비동기 인덱싱
DB 트랜잭션과 ES 인덱싱을 분리하고, 그 사이를 메시지 큐로 연결합니다.
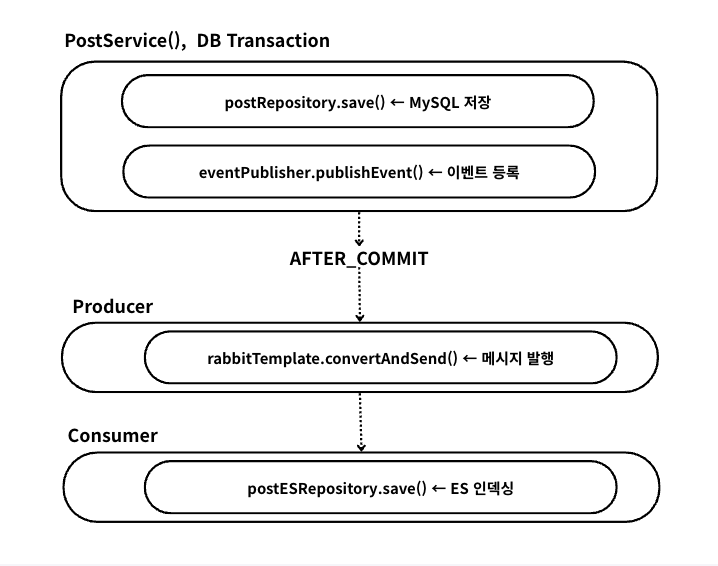
구현한 세부 코드입니다.
1. 이벤트 정의
public record PostIndexEvent(
Long postId,
String title,
String content,
String authorName,
LocalDateTime createdAt,
EventType eventType
) {
public enum EventType { INDEX, UPDATE, DELETE }
public static PostIndexEvent index(Post post) {
return new PostIndexEvent(
post.getId(), post.getTitle(), post.getContent(),
post.getUser().getNickname(), post.getCreatedAt(), EventType.INDEX
);
}
public static PostIndexEvent update(Post post) {
return new PostIndexEvent(
post.getId(), post.getTitle(), post.getContent(),
post.getUser().getNickname(), post.getCreatedAt(), EventType.UPDATE
);
}
public static PostIndexEvent delete(Long postId) {
return new PostIndexEvent(postId, null, null, null, null, EventType.DELETE);
}
}
게시글의 생성, 수정, 삭제 각각에 대응하는 이벤트 타입을 정의했습니다. delete의 경우 인덱스에서 제거만 하면 되므로 postId만 전달합니다.
2. 서비스에서 이벤트 발행
@Transactional
public PostResponse create(Long userId, PostCreateRequest request) {
Post post = Post.create(user, request.title(), request.content());
Post savedPost = postRepository.save(post);
eventPublisher.publishEvent(PostIndexEvent.index(savedPost));
return PostResponse.from(savedPost);
}
publishEvent()는 Spring의 ApplicationEventPublisher를 통해 이벤트를 등록만 합니다. 이 시점에서는 메시지가 발행되지 않습니다.
3. 트랜잭션 커밋 후 메시지 발행
@Component
@RequiredArgsConstructor
public class PostIndexingProducer {
private final RabbitTemplate rabbitTemplate;
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
public void handle(PostIndexEvent event) {
rabbitTemplate.convertAndSend(
RabbitConfig.COMMUNITY_EXCHANGE,
RabbitConfig.COMMUNITY_POST_ROUTING_KEY,
event
);
}
}
여기서 @TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)는 트랜잭션이 성공적으로 커밋된 이후에만 실행됩니다. DB 저장 중 예외가 발생하여 롤백되면 리스너가 호출되지 않으므로 DB에 없는 데이터가 ES에 인덱싱되는 상황을 방지할 수 있습니다.
4단계: 컨슈머에서 ES 인덱싱
@Component
@RequiredArgsConstructor
public class PostIndexingConsumer {
private final PostESRepository postESRepository;
@RabbitListener(queues = RabbitConfig.COMMUNITY_POST_QUEUE)
public void handle(PostIndexEvent event) {
switch (event.eventType()) {
case INDEX, UPDATE -> postESRepository.save(
PostDocument.of(event.postId(), event.title(), event.content(),
event.authorName(), event.createdAt())
);
case DELETE -> postESRepository.deleteById(String.valueOf(event.postId()));
}
}
}
RabbitMQ 큐를 구독하는 컨슈머가 이벤트 타입에 따라 ES에 인덱싱하거나 삭제합니다. INDEX와 UPDATE는 save()로 동일하게 처리되는데, ES의 save()는 동일 ID가 있으면 덮어쓰는 upsert 방식으로 동작하기 때문입니다.
도입효과
- Nori 형태소 분석기를 통해 “우선순위큐”, “우선 순위 큐” 등 띄어쓰기와 조사에 관계없이 동일하게 검색 가능
- 스코어링과 필드 부스팅(
title^2)으로 제목에 키워드가 포함된 글이 상위에 노출 - 비동기 인덱싱 구조로 ES 장애가 게시글 CRUD에 영향을 주지 않음
논의점
현재는 AFTER_COMMIT을 통해 “DB에 없는 데이터가 ES에 인덱싱되는 문제”는 확실하게 해결합니다. 하지만 반대 방향, 즉 “DB에 있는 데이터가 ES에 인덱싱되지 않는 문제”는 해결하지 못합니다.
이를 더 개선하려면 Transactional Outbox Pattern을 고려할 수 있습니다. 이벤트를 RabbitMQ로 직접 보내는 대신 DB의 outbox 테이블에 함께 저장하고 별도의 릴레이 프로세스가 outbox를 폴링하여 메시지를 발행하는 방식입니다. 이렇게 하면 DB 트랜잭션과 이벤트 저장이 원자적으로 이루어져 메시지 유실 없는 인덱싱을 보장할 수 있습니다.
현재 커뮤니티 규모에서는 AFTER_COMMIT + DLQ 조합으로 충분하다고 판단했지만 검색 정합성이 더 중요해지는 시점에서는 어렵지만 Outbox Pattern으로의 전환을 검토해보아야 할 것 같습니다.